Stop Chasing 100% Occupancy in Support Teams

A GZP Reality Check
Humans plateau near 85%. Software can run near 99%. The win comes from designing the handoff.
TL;DR
• Human agents rarely sustain much above ~85% occupancy without quality loss and churn.
•Software-driven capacity can run close to 99% on bounded, verifiable work.
• Hybrid models work when occupancy targets differ by work type, not averaged across the whole team.
• Routing rules and escalation packets decide success more than headcount does.
• Governance stays lightweight when it focuses on recontact, bounce rate, and defects.
• A kill switch and change control prevent high-speed failure.
- Occupancy is one of those numbers that feels like discipline. It is clean. It is easy to compare across teams. It sits nicely in a weekly deck. It also tempts leaders into the wrong fight.
- Most support teams have lived the same loop. Push occupancy up. Celebrate the first week. Watch quality slip in the second. See reopens grow. Hear managers complain about burnout. Lose a few strong agents. Fill gaps with new hires. Repeat.
- The reason this keeps happening is not that people are weak or managers are lazy. It is that human work has physics. There is a ceiling where sustained load starts to tax judgment, patience, and memory. Many teams find that ceiling around 85%. Some stabilize a bit lower. Some can run a bit higher for short bursts. The pattern is consistent. Past a point, the system collects a debt that shows up later as defects and attrition.
- Software-driven agents behave differently. They do not fatigue. They do not need recovery. They can keep pulling from the queue at a consistent pace. When the work is bounded and verifiable, that capacity can run near 99% occupancy. That does not make it universally safe. It makes it a different kind of capacity.
- That gap between 85% and 99% is where the math starts to favor hybrid models. Not as a slogan. As an operations design choice.
Occupancy capacity math (simple)
Assume:
- 100 human agents
- 8 hours/day
- Human occupancy target: 85%
- Software-driven occupancy target: 99%
Busy hours per day:
- Humans: 100 × 8 × 0.85 = 680 busy hours
- Software layer equivalent: 100 × 8 × 0.99 = 792 busy hours
- Difference: 112 busy hours/day (about 16% more busy time)
If average handle time is 12 minutes (0.2 hours):
- Extra resolved cases/day ≈ 112 / 0.2 = 560 cases/day
That math only holds when the work is repeatable and the outcome can be checked. Without verification, higher occupancy can also mean higher error volume.
The rest of this piece is about making sure the extra capacity turns into real outcomes: faster responses, fewer recontacts, and calmer teams.
Treat occupancy as a constraint, not the goal
Occupancy measures how much logged-in time is busy. It does not measure whether the work stuck. It does not measure whether the customer had to come back. It does not measure whether the agent left the next agent a usable trail.
That is why occupancy makes teams brittle when it becomes the main target. Teams start shaving the wrong things.
Notes get thinner because they feel like “non-productive time.” Customers get rushed because speed becomes the proxy for value. Edge cases get punted to another queue to protect handle time. Supervisors stop coaching because coaching lowers occupancy.
Then the backlog grows anyway, because rework grows.
This is where leaders get confused. The team looks fully loaded. Yet outcomes worsen. That is not a contradiction. It is a predictable result of pushing humans past a sustainable duty cycle.
Humans need slack for work that is invisible on a timer:
- investigation and cross-checking
- documentation another person can trust
- coaching and calibration
- recovery after hostile interactions
- knowledge refresh after policy changes
- surge absorption when volume spikes
- incident work that steals time from the queue
If that slack is not planned, the system creates it through sick days, attrition, and avoidable reopens.
Software-driven capacity changes the constraint set. It can run near full duty cycle, but it needs different protections. It needs clear entry rules, clear exit rules, and visible failure handling. When those are weak, high occupancy becomes high-speed defects.
A stable hybrid model accepts both truths at the same time.
Put work in the right lane instead of arguing about “automation”
Most teams start this topic by debating ideology. Replace or assist. Human or machine. Centralize or decentralize. Those debates burn time and settle nothing.
The practical question is simpler. Which work can be bounded tightly enough to run at high machine occupancy, and which work needs human judgment because the cost of a wrong outcome is higher than the cost of capacity.
A short sorting table forces clarity.

This table is not about being conservative. It is about being explicit. “Risk if wrong” should be defined in business terms: money, legal exposure, safety, and customer trust.
“Verification” is the deciding column. If an outcome cannot be verified, it should not run at 99% occupancy. It can still help, but it should help inside a human workflow rather than replace it.
Design routing like a product, not a queue rule
Hybrid operations fail at the seams. They fail when routing is fuzzy, handoffs are messy, and nobody owns drift. Most of the value lives in the flow design, not in the staffing plan.
A simple routing model can carry most teams a long way.
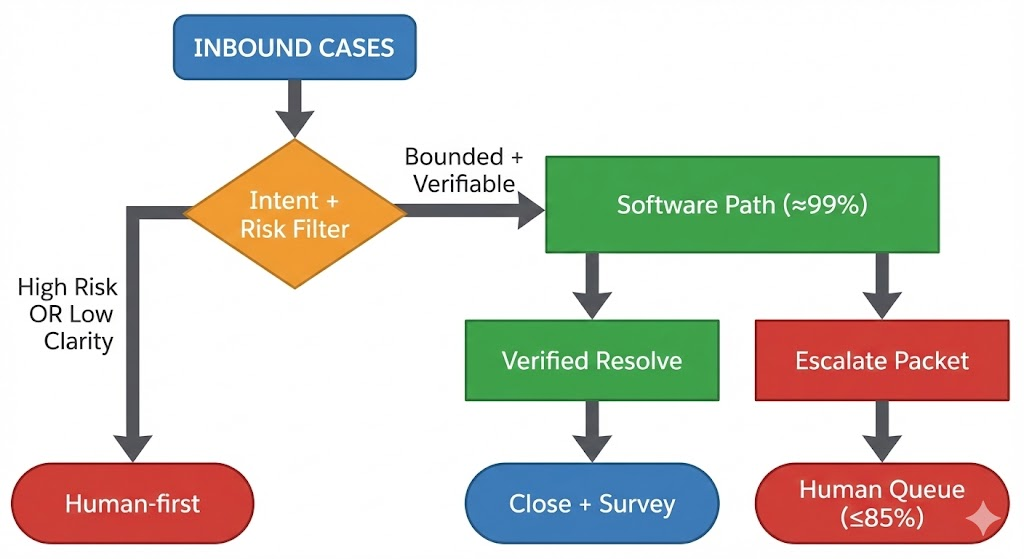
Two rules make this flow work.
First, entry rules prevent silent risk. A case should only enter the high-occupancy path if it meets specific conditions. Those conditions should be testable and logged. If the team cannot explain why a case went down a path, the system is already drifting.
Second, exit rules prevent stuck work.
Every path needs a definite end state:
Resolved with proof, escalated with a complete packet, or paused with a scheduled follow-up.
Without those rules, hybrid becomes a bounce machine. Bounce is where occupancy “wins” and customers lose.
Reduce variance in the human queue to protect quality
Support leaders often focus on averages: average handle time, average speed to answer, average occupancy. The queue does not run on averages. It runs on variability.
Two weeks with the same total volume can feel completely different depending on the shape of arrivals and the mix of work.
When arrivals spike, the queue needs spare capacity to recover. Machines can absorb spikes without fatigue when the work is bounded. Humans need slack to keep judgment stable.
Hybrid designs often win because they reduce variance in the human queue. The machine layer takes the high-volume, low-risk, waiting-heavy work. Humans then see a smaller queue with a clearer set of exceptions. That decreases context switching and rework, even if handle time per case is higher.
That is why the model can improve both speed and quality at the same time. Not because humans suddenly become faster. Because the queue becomes less chaotic.
Make the escalation packet the center of the system
Handoffs decide whether hybrid is faster or slower than a human-only team. A weak handoff forces humans to re-ask basic questions. That is wasted time and a bad customer experience.
Treat the escalation packet as a product spec. Keep it short. Enforce completeness. Make it visible.
Escalation packet (minimum fields)
- Customer intent (one sentence)
- Account or order identifiers
- What was already attempted (3 bullets max)
- Evidence captured (logs, timestamps, screenshots)
- Policy path used (name + version or date)
- Remaining unknowns (what blocks closure)
- Suggested next step (one action)
One enforcement line changes behavior:
If any field is blank, the case stays in intake until filled.
That is not punishment. It is flow control. It stops the bounce rate from becoming a silent tax on humans.
This packet spec also makes coaching easier. A supervisor can scan a case and see whether the system is failing on intake, tools, or policy clarity. That reduces debate and speeds fixes.
Measure outcomes that cannot be faked
When occupancy is the main metric, teams learn how to look busy. When outcomes are the main metric, teams learn how to close the loop.
A small set of measures is enough if they are chosen well:
- recontact within 7 and 30 days
- escalation bounce rate (handoff quality)
- time to first response (customer experience)
- compliance defects per 1,000 cases (risk)
- customer satisfaction variance (stability), not only the average
- time-to-restore for incident-driven work (resilience)
A compact “before and after” panel helps leaders stop arguing about activity and start looking at system health.

These numbers are an example structure. The point is the pairing: outcomes plus the mechanism that drove them. If the team cannot connect a metric shift to a process change, the metric is just noise.
Sampling matters here. Sample both human-handled and machine-handled work. Oversample edge cases and new intents. Calibrate weekly early on, then move to a steady cadence. This keeps drift visible.
Set different occupancy targets by queue to avoid hidden damage
One reason occupancy becomes a blunt instrument is that teams apply one target to all work. That pushes complex queues into trouble and underuses simple queues.
A steadier approach is to set targets by work type:
- high-risk or ambiguous work: lower occupancy target to protect judgment
- bounded and verifiable work: high software occupancy with strong controls
- mixed queues: hybrid paths, with explicit thresholds for routing
This also helps workforce planning. It turns occupancy from a demand for “more efficiency” into a design choice that matches risk.
It also removes the moral tone. Human slack stops looking like waste and starts looking like resilience.
Handle leadership concerns without turning this into a culture war
Hybrid designs can create real people problems when the work mix is not managed.
If all easy work goes to machines, humans get only angry, complex, high-emotion cases. That raises stress and churn. It also creates a skill trap where new hires never see simpler work and never build confidence.
Fixes exist and they are operational:
- rotate humans across queues to keep a balanced work diet
- keep a slice of “easy wins” in the human lane for pacing
- use software assistance inside complex cases to reduce grind
- track workload by agent, not only by team averages
Compliance teams often raise a second concern: accountability. That is fair. A good pattern here is review-first on regulated decisions. Software gathers facts, checks eligibility, and drafts the output. Humans approve the decision and sign it. This keeps speed while preserving ownership.
There is also the fear of brittleness. That fear is earned when routing rules are stale and exceptions pile up in the dark. The answer is not avoiding high-occupancy paths. The answer is owning change control.
When policies change, the machine path must update quickly. If policy updates take weeks to reach the automated lane, defect rates will spike in a way that looks “mysterious” in dashboards. It is not mysterious. It is drift.
Use a simple decision tree to keep debate short
This fits well mid-article when attention starts to dip. It also gives leaders a rule they can repeat.
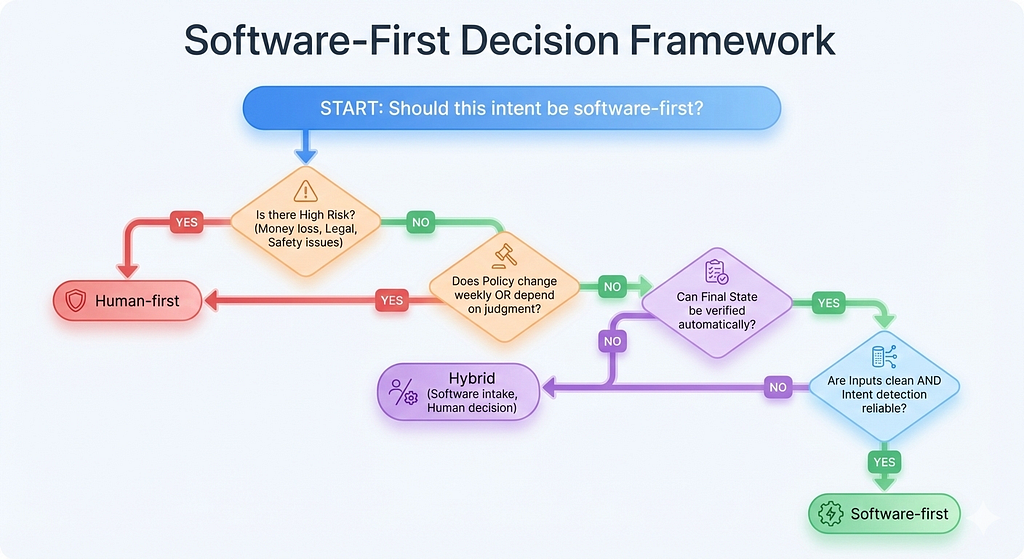
Should this intent be software-first?
- If wrong outcome causes money loss, legal risk, or safety risk → Human-first
- If policy changes weekly or depends on judgment → Human-first
- If the final state can be verified automatically → go to next check
- If inputs are clean and intent detection is reliable → Software-first
- Otherwise → Hybrid (software intake, human decision)
This is not perfect. It is good enough to prevent the common mistake of sending high-risk ambiguity down a high-speed lane.
Plan for failure modes instead of hoping for stability
Every hybrid program runs into the same break points. Writing them down early prevents surprise and blame.
Where hybrid programs break
- routing rules get stale after policy changes
- exceptions get ignored and become a shadow backlog
- software paths close cases without verification
- humans inherit only angry edge cases and churn rises
- no kill switch during incidents, so defects scale fast
These are not “people problems.” They are ownership problems.
A stable design assigns clear owners for:
- routing and thresholds
- knowledge and policy freshness
- quality sampling and coaching
- incident playbooks and fallback routing
Teams do not need more committees. They need a few named owners with clear authority.
A kill switch is part of that authority. When an incident hits or a tool slows down, routing should change quickly. If the system cannot degrade safely, it will fail loudly.
Roll out in stages so learning stays clean
The fastest way to damage trust is a big bang release that creates messy outcomes and unclear accountability. A staged rollout is slower on paper and faster in reality.
A practical sequence starts with the least risky layer. Intake.
Intake and triage are where machines usually help without increasing risk. They can collect facts, categorize cases, and route to the right lane. This alone reduces handle time and improves first response time, because humans start with a clearer case file.
Then add a small number of bounded intents where verification is easy. Measure recontact and defects. Tighten entry rules. Improve escalation packets. Expand only when outcomes stay stable.
This approach also makes metrics honest. If expansion happens gradually, it is easier to see which change caused which effect.
A Hybrid rollout checklist
- Pick 3 bounded intents with clear verification
- Define entry rules and exit rules for those intents
- Implement escalation packet fields and enforce completeness
- Set human occupancy targets by queue, not one target for all
- Start weekly QA sampling for 6–8 weeks, oversampling edge cases
- Add a kill switch and an incident routing plan
- Expand coverage only when recontact stays flat or drops
This is the core. It works because it respects the physics of human work and uses high-occupancy capacity where verification is possible.
The win is not 99% for everything. The win is a queue that clears faster with fewer reopens, and a team that can handle a bad week without breaking. That is what sustainable efficiency looks like in support operations.
Stop Chasing 100% Occupancy in Support Teams was originally published in GZP Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.